Part 4 Series of Elasticsearch Cluster on Spot Instances with zero downtime in App?
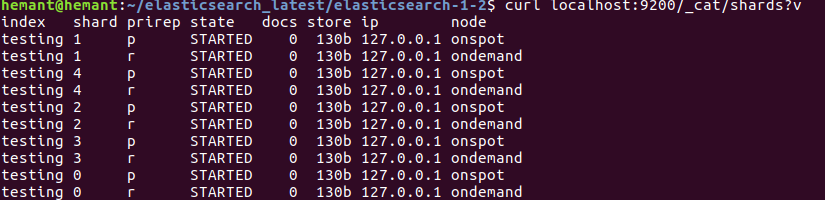
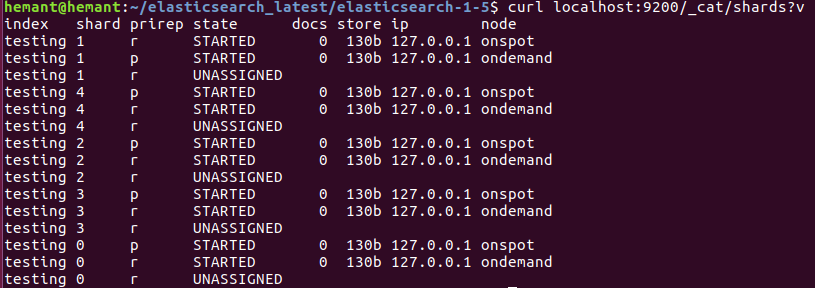
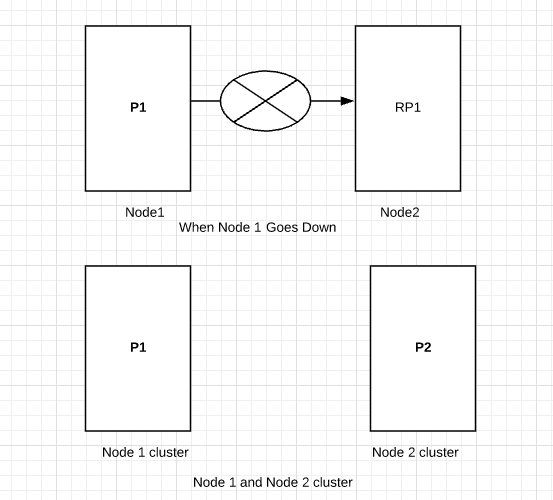
Shard allocation concept can help us to use spot instance on Elasticsearch Data nodes: By using rack feature in elasticsearch node we can tell that primary shard to be on one rack and its replica shard to be on another rack. Like as per our elasticsearch setup we have divided ondemand rack and spot rack as per below elasticsearch.yml configuration. elasticsearch.yml for ondemand rack: cluster.name: my-application-1 node.name: ondemand path.data: /data/elasticsearch-1-2 path.logs: /var/log/elasticsearch http.port: 9200 node.master: false node.data: true node.attr.rack_id: ondemand cluster.routing.allocation.awareness.attributes: rack_id discovery.zen.ping.unicast.hosts: ["nb-master-es1.testing.com", "nb-master-es2.testing.com",”nb-master-es3.testing.com”] elasticsearch.yml for onspot rack: cluster.name: my-application-1 node.name: onspot path.data: /data/elasticsearch-1-5 path.logs: /var/log/elasticsearch http.port...